
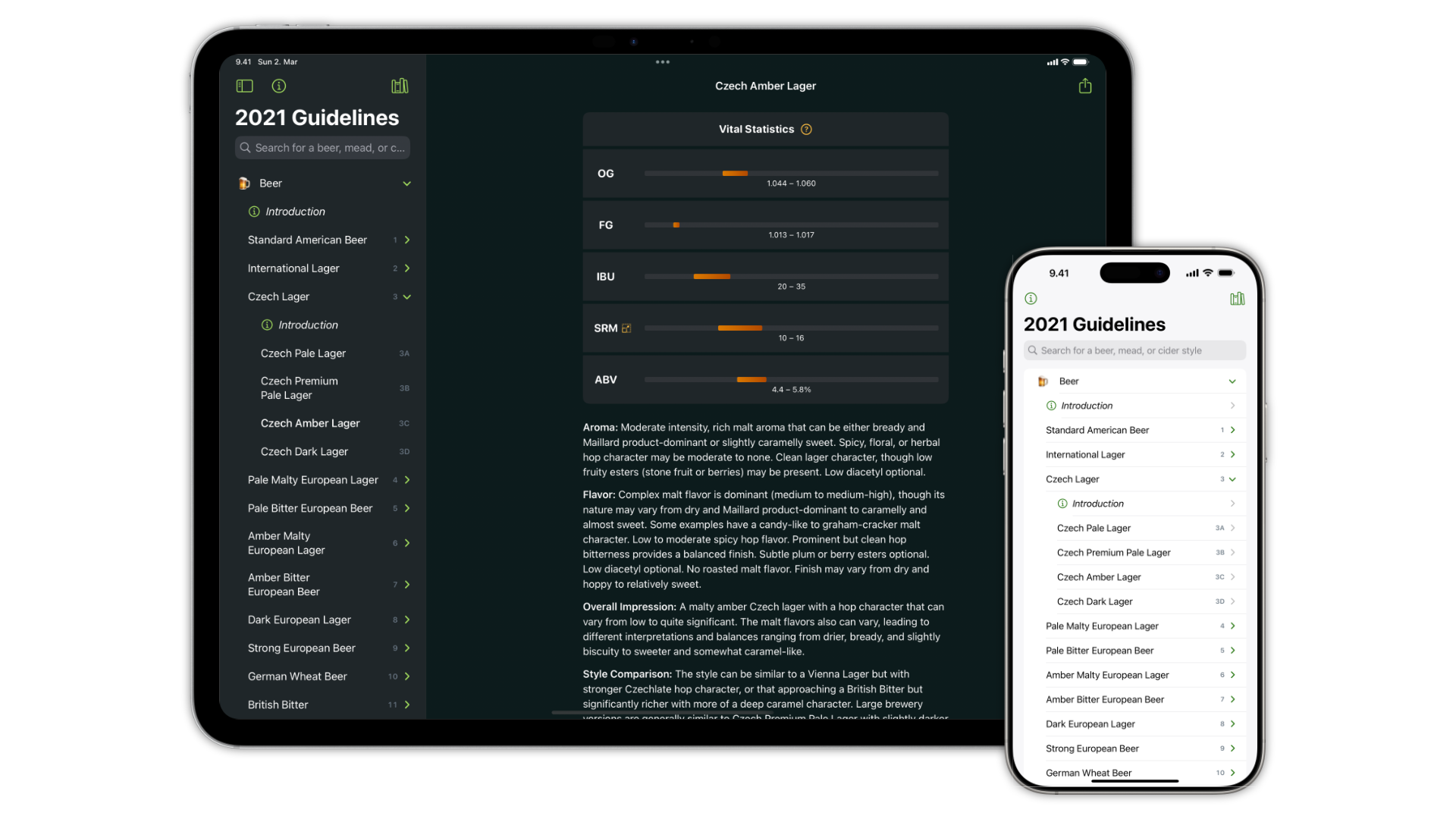
Due to circumstances beyond my control, Piranhas has unfortunately been discontinued.
Over the years, running this service has become increasingly difficult.
First of all, over the years Piranhas has lost access to some Amazon alternatives. Book Depository was first purchased by Amazon and then shut down entirely. Wordery summarily shut down their affiliate programme and API access and is in fact not operating at all at the time of writing.
Secondly, Amazon has done their best to obfuscate shipping costs until the last moment in the checkout process. There was never an easy way to get programmatic access to shipping costs, but it was possible to do so with a bit of manual labour. However, this is no longer possible as they don’t publish comprehensive shipping costs anymore (the shipping costs vary based on individual items).
The final, and fatal, issue is that Piranhas has, without advance notice, lost access to the Amazon Product Advertising API. Without PA API access, it is impossible to search for books or look up prices for them. My Amazon affiliate account remains in good standing but price comparison sites are apparently not something that Amazon wishes to encourage.
So long, and thanks for all the fish,
Matias
P.S. feel free to buy something through one of these affiliate links if you’d like to send a final bit of affiliate income my way: 🇺🇸 Amazon.com, 🇬🇧 Amazon.co.uk, 🇨🇦 Amazon.ca, 🇩🇪 Amazon.de, 🇫🇷 Amazon.fr, 🇪🇸 Amazon.es, or 🇮🇹 Amazon.it
P.P.S. this post is a copy of the EOL message on piranhas.co

![Spam email from ChartDB:
[snip]
P.S.: REDACTED here, co-founder of ChartDB. Why I decided to send you this email? You starred ChartDB on GitHub 💛](/_bridgetown/static/chartdb-FT66XVPP.png)
